





AI is increasing output across delivery: faster specs, compressed release cycles, smaller teams covering more ground. What is not keeping pace is the reliability and assurance layer around that output. Whether what shipped is traceable to requirements, whether the risk of a given release is visible before it surfaces in production, whether anyone in the room can answer “are we safe to go?” with real confidence.
Most enterprises have programs. Very few have portfolio intelligence. The gap between the two is where risk accumulates, silently, until it matters.
The problem is structural
Tests run. Results appear. No executive can open a single view and answer: what is our release risk across all programs? Metrics exist in isolation. The board sees nothing actionable. Program visibility depends on whoever assembled the status report that week.
Organizations invest in AI-assisted delivery. But in a compliance review or a post-incident audit, few can show which requirements were covered, which releases they mapped to, and where the exposure was. Without traceability, execution spend has no governance value. It is activity, not assurance.
Dev teams move faster every quarter. Release risk grows alongside that speed, invisibly. By the time a production failure surfaces, the window for prevention has passed.
Introducing InfoBeans RAI
We built InfoBeans RAI as a reliability and assurance layer designed to sit across AI-led delivery. It connects specification, execution, and reporting into one enterprise-grade system so that results are traceable, release decisions carry real signal, and leadership has a single view of program risk.
Traceability and control sit above it all: every meaningful action is logged, confirmed before execution, and attributable to a specific run, requirement, and decision point. This is what turns execution into assurance.
Why QA automation is the starting point?
We are applying RAI first in QA automation because it sits at the intersection of all three structural problems. It is where specifications meet execution, where execution should feed reporting, and where gaps in traceability are most costly and most common.
The outcomes are measurable. In a regulated financial services program, sequential test runs that had grown to nearly 29 hours were restructured into parallel pipelines. The same volume completed in under 13 hours, a 60% reduction, in the first deployment cycle. Triage time dropped from over an hour per run to under 15 minutes. Setup that previously took four to six weeks was done in under two days.
Our benchmarks across deployments target 60% efficiency gains in execution, 30% reduction in maintenance costs, and QA engineer onboarding compressed to half a day. Early programs are tracking toward those numbers.
The pattern holds across verticals. A global logistics company migrating from a traditional transportation management system to a cloud platform encountered the same structural gaps: fragmented coverage, no traceability to requirements, and release risk that only surfaced after something broke in production. A proof of concept completed with that team validated the same benchmarks:
The white-glove model: side-by-side from day one
Pure self-serve does not work here, and that is not a limitation of the product. Enterprise QA environments are fragmented: tools are disconnected, configurations are undocumented, and context lives in the heads of the people who built the workflows. Every new project typically rebuilds automation from scratch. Drop a platform into that environment without guided setup and the pattern continues.
We operate alongside the team. Our engineers run the deployment, connect the integrations, establish the review cadence, and operate the system through steady-state. This is what changes adoption speed and what makes outcomes stick.
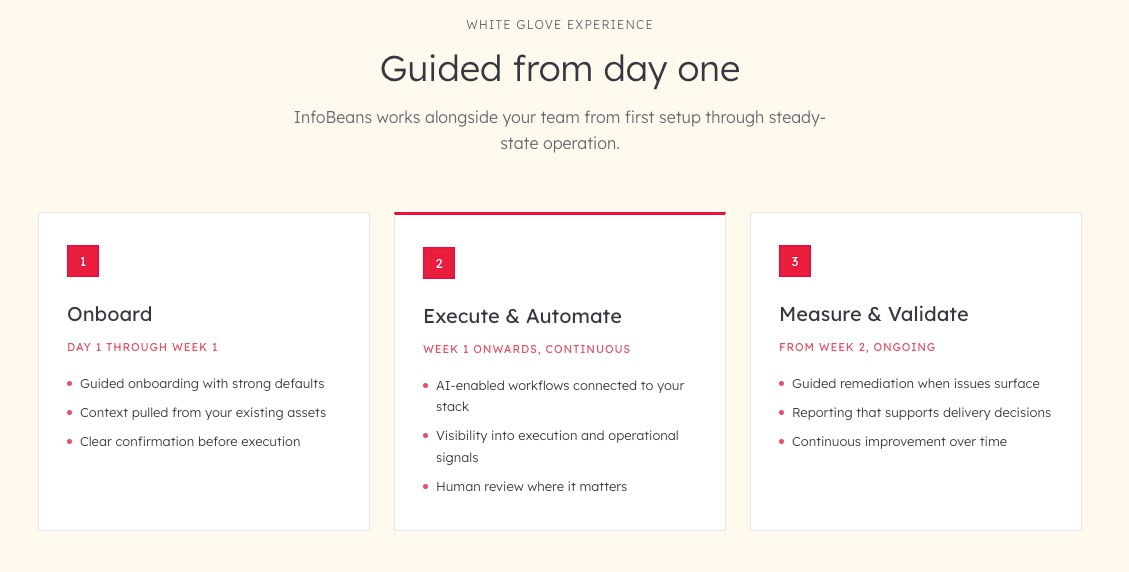
Onboard (Day 1 through Week 1). Configuration is derived from existing specs, repos, and assets. BRD or Swagger inputs flow into a generated test suite. Jira, GitHub, and Slack are connected in minutes. Nothing runs without explicit review and confirmation.
Execute and Automate (Week 1 onward). Playwright and pytest run tests across UI, API, and database in parallel, results streaming live to the CI/CD pipeline. When locators break, Azure OpenAI suggests the fix, applies it, and re-runs without manual intervention. CI pipelines that averaged 25 to 45 minutes compress to 10 to 18 minutes.
Measure and Validate (Week 2 onward). Allure, HTML, and PDF reports are generated per run. Executives see a release risk score before every deployment. QA Directors see coverage deltas and full requirement-to-test traceability. Engineers see categorized failure triage with guided follow-up. Jira X-ray stays current without manual sync.
Your team has full ownership of results, control of every run, and access to all source code and configuration.
How the system works?
The accelerator is packaged for deployment with no separate server required. A commit triggers the workflow, which calls the platform. It plans, executes, reviews, and heals, then pushes results to Jira, Allure, and Teams. Screenshots, tracebacks, and logs are captured on every failure. The audit trail runs from requirement to test to result to release.
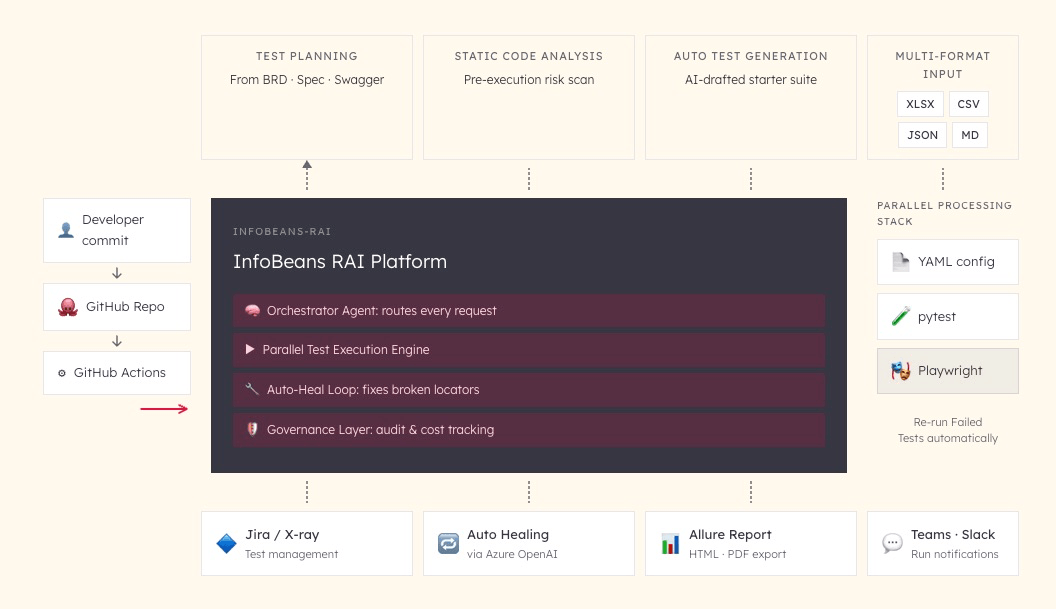
The Orchestrator Agent routes requests from MCP-compatible AI IDEs or the guided wizard, passing every action through an audit and control layer before reaching the execution engine. On completion, artifacts flow outward: reports to Allure, status to Jira and X-ray, notifications to Teams or Slack. The platform is MCP-native, so engineering teams can call it from Claude, Codex, or Gemini Code Assist without switching context.
What changes when this works?
The shift is not just in speed. It is in what people stop doing and what they start doing instead.
QA engineers who spent their shifts monitoring sequential test runs are now directing agents and spending time on coverage strategy. Teams that rebuilt automation from scratch for every project start from a working base. Organizations that could only confirm tests ran can now answer: what was the release risk, which requirements were validated, and where does exposure remain?
In the financial services program above, business teams stopped waiting a full day to see if a change worked. Engineers stopped losing mornings to overnight locator repairs. The QA Director stopped assembling the release status report by hand. That is a different working week, not just a faster one.
Reliability beyond automation
The reliability and assurance layer does not stop at test execution. The same principles of governed execution, traceability, and continuous insight apply wherever AI is running consequential work at scale.
DevOps and site reliability engineering
For SRE and DevOps teams, environment monitoring, node health, and CPU alerting run through the same governed pipeline as test execution, with full traceability extending from results to infrastructure events.
Performance and load testing
Reliability under load is a failure mode automation alone does not surface. Performance test execution, tracked and reported through the same layer, closes a gap most teams currently manage manually.
Security and infrastructure
In manufacturing, logistics, and regulated industries, uptime and security posture carry compliance weight beyond the release cycle. RAI extends the same governed view to cover delivery, operations, and risk.
Close the reliability and assurance gap
Your teams are moving faster. The reliability and assurance layer needs to keep pace. When traceability is inconsistent, risk stays invisible until it hits production, and assurance remains a gate your leadership reacts to rather than a continuous insight stream they can act on.
We built InfoBeans RAI to close that gap. We have run this inside real delivery programs and we know what a strong reliability and assurance layer makes possible. If your board is asking questions your delivery teams cannot yet answer with confidence, that is exactly the problem we built this for.





